NOTE: Output order of the three separated signals are aligned with the ground-truth audios (two speech and a noise).
1-source mixture
Mixture 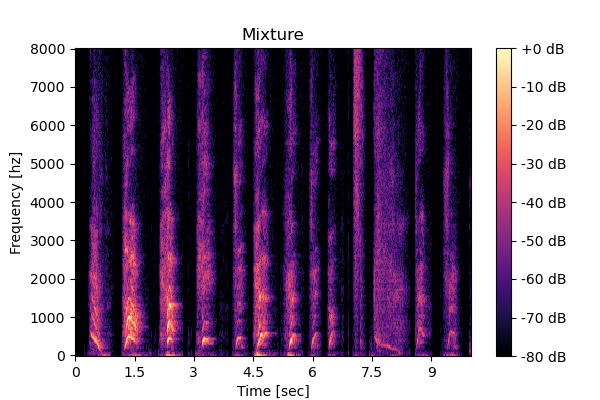 |
Clean source1 (= Mixture) 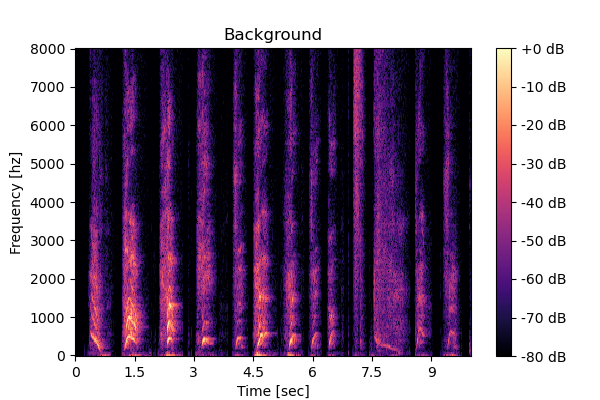
|
MixIT
Output 1 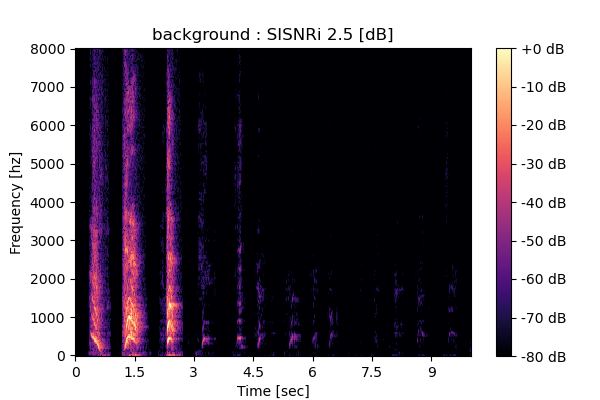
|
MixIT + Sparsity loss
Output 1 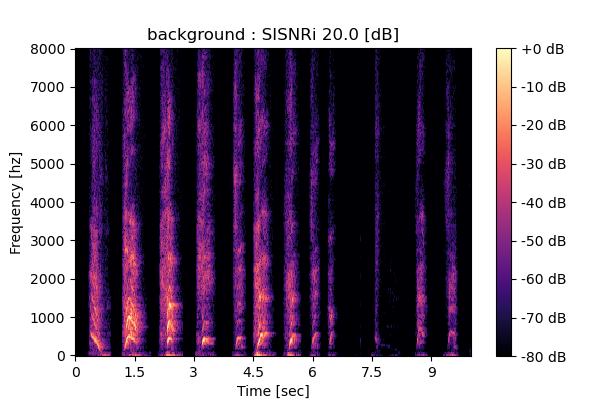
|
Self-Remixing (+ CBS) from scratch
Output 1 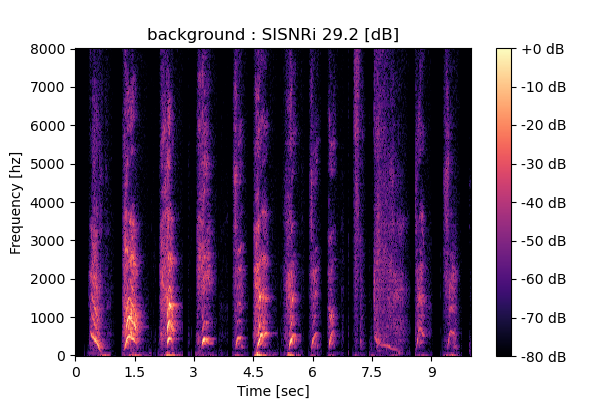
|
Self-Remixing (+ CBS), fine-tuning MixIT pre-trained model
Output 1 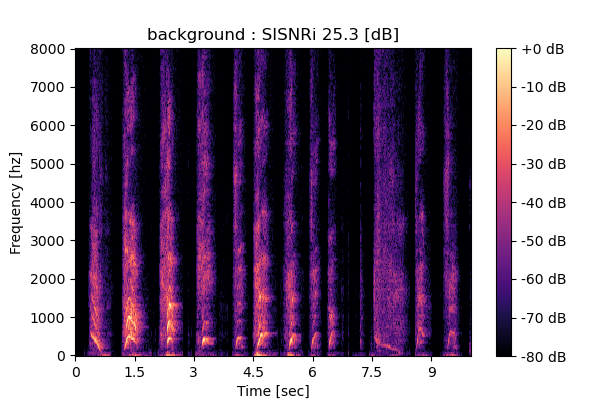
|
2-source mixture
Mixture 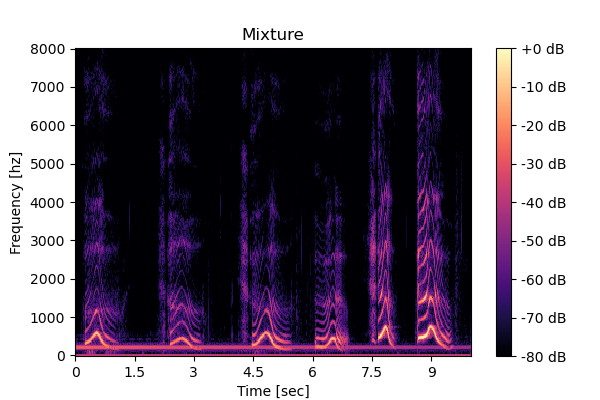 |
Clean source 1 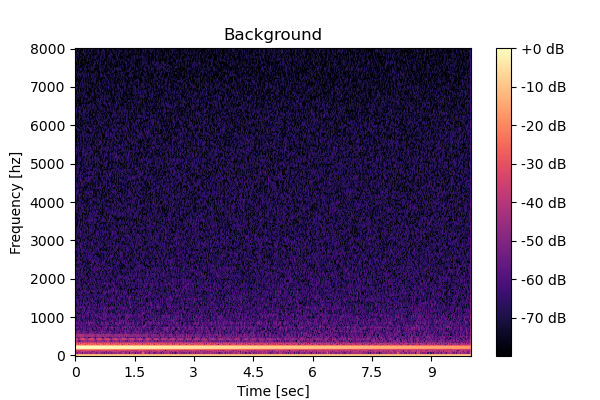
|
Clean source 2 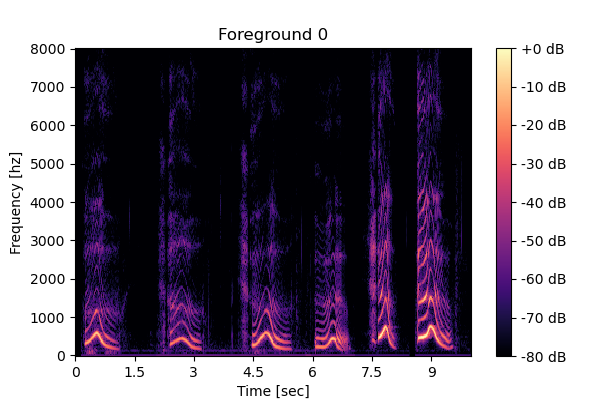
|
MixIT
Output 1 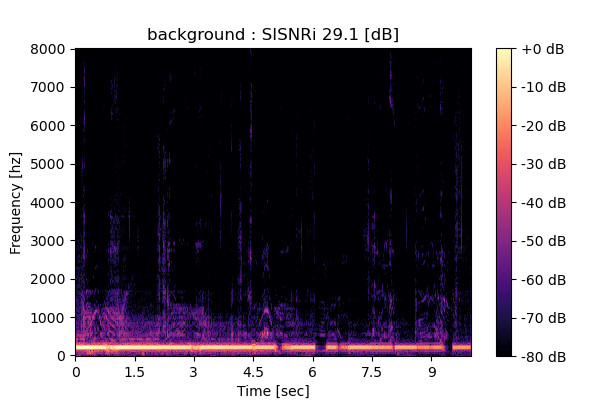
|
Output 2 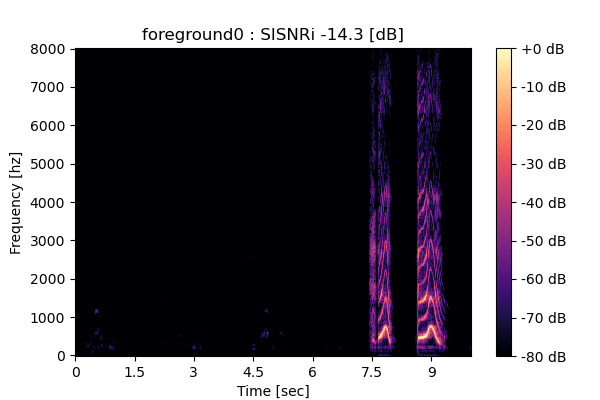
|
MixIT + Sparsity loss
Output 1 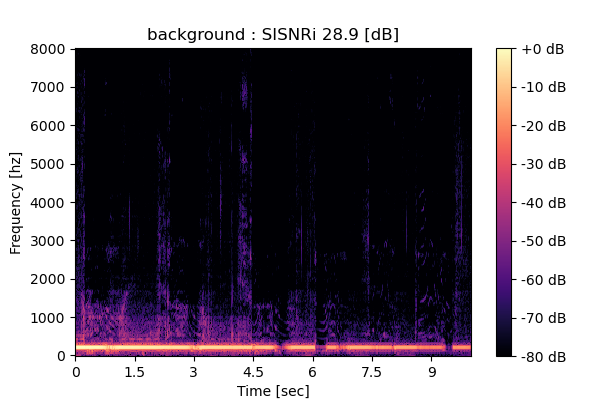
|
Output 2 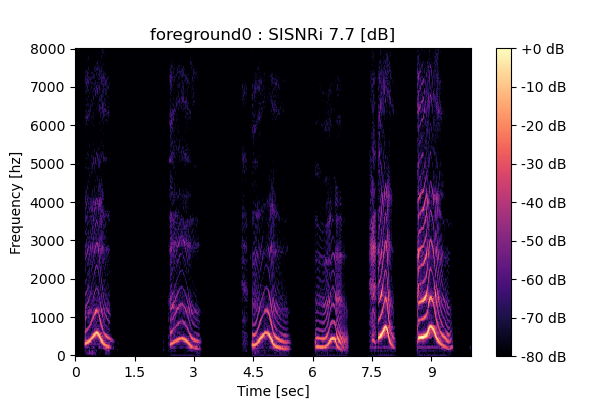
|
Self-Remixing (+ CBS) from scratch
Output 1 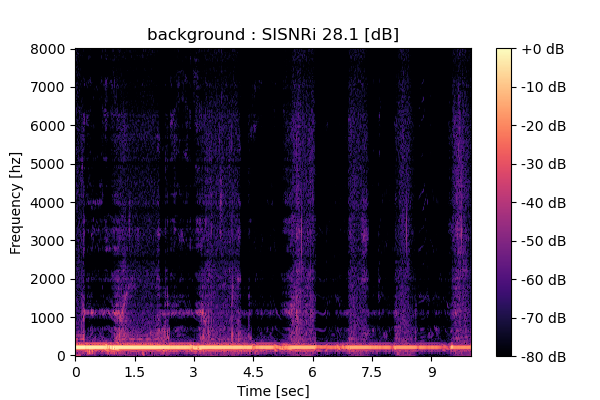
|
Output 2 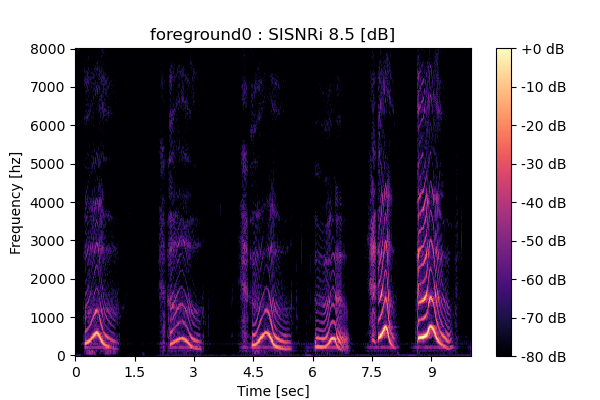
|
Self-Remixing (+ CBS), fine-tuning MixIT pre-trained model
Output 1 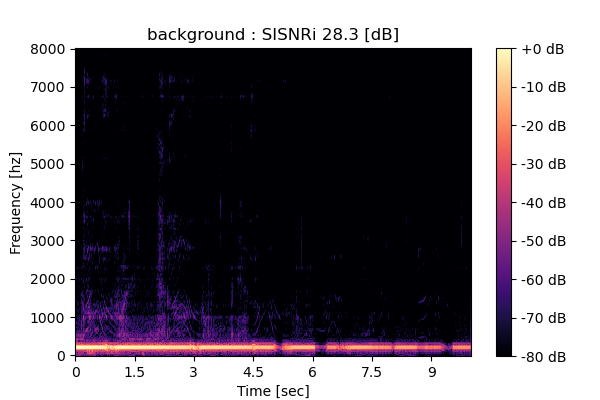
|
Output 2 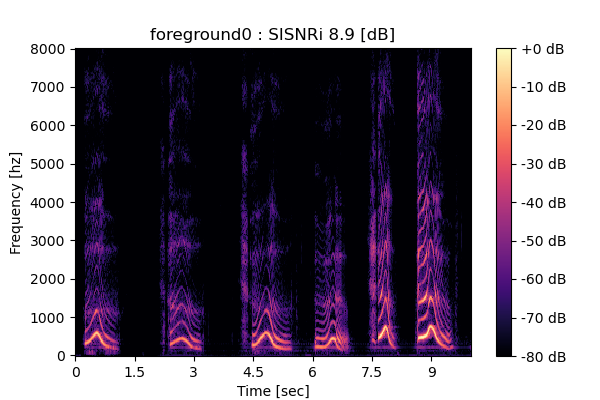
|
3-source mixture
Mixture 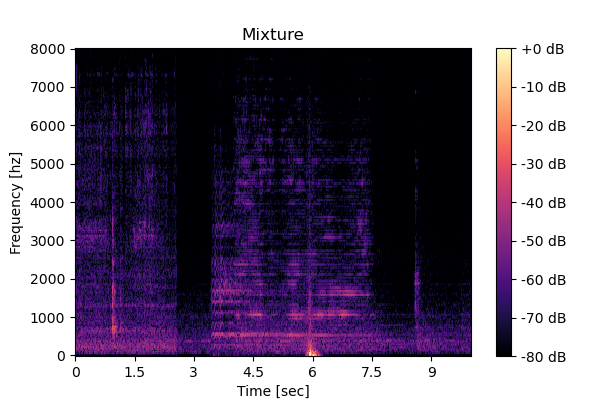 |
Clean source 1 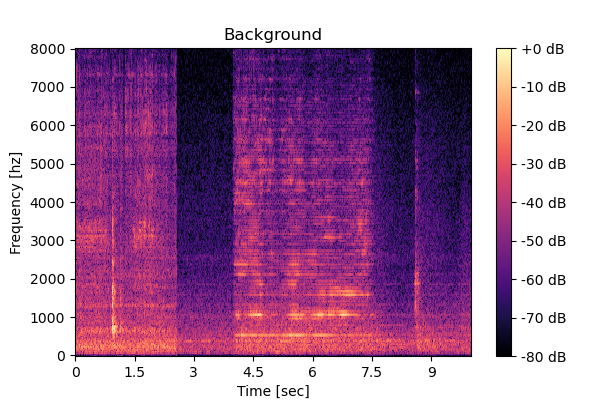
|
Clean source 2 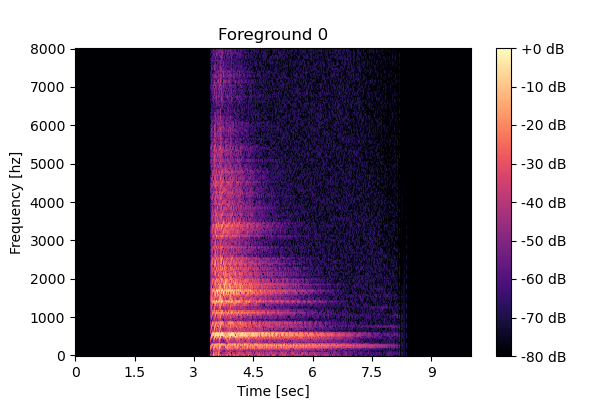
| Clean source 3 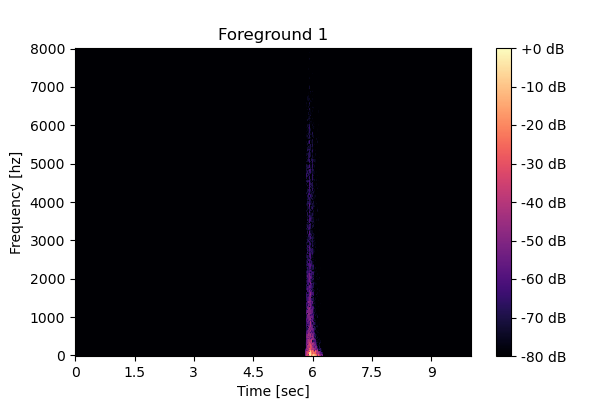
|
MixIT
Output 1 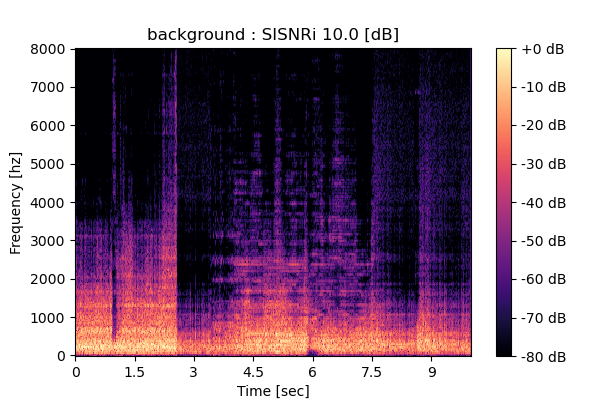
|
Output 2 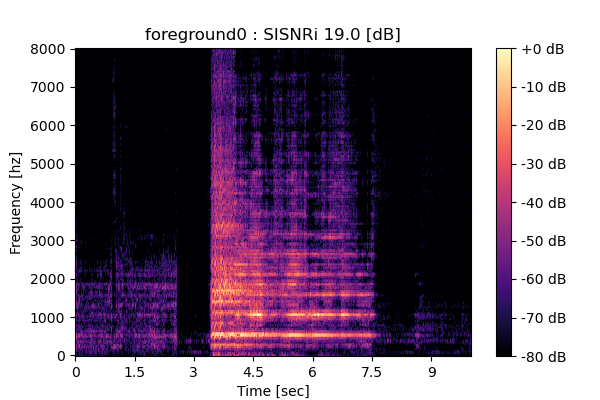
|
Output 3 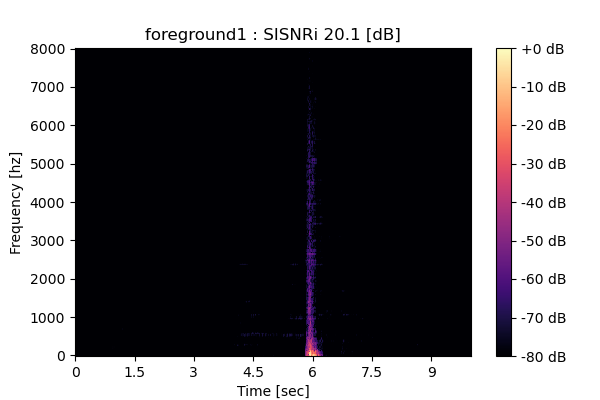
|
MixIT + Sparsity loss
Output 1 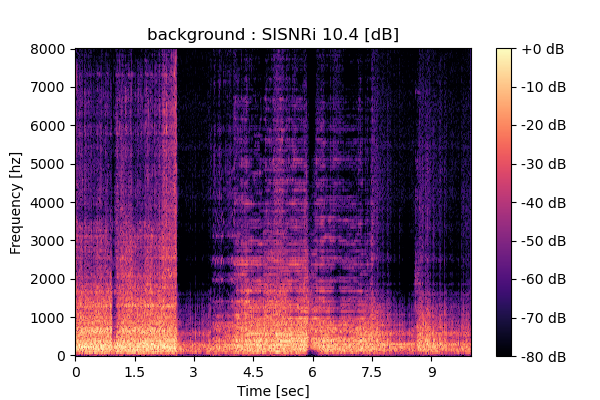
|
Output 2 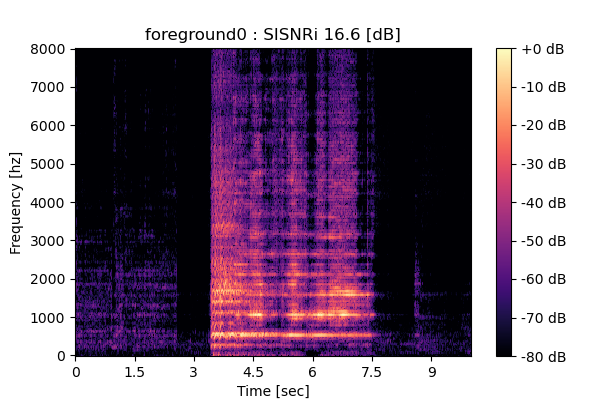
|
Output 3 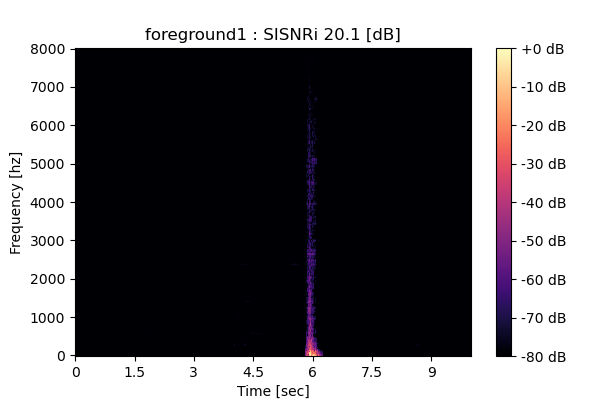
|
Self-Remixing (+ CBS) from scratch
Output 1 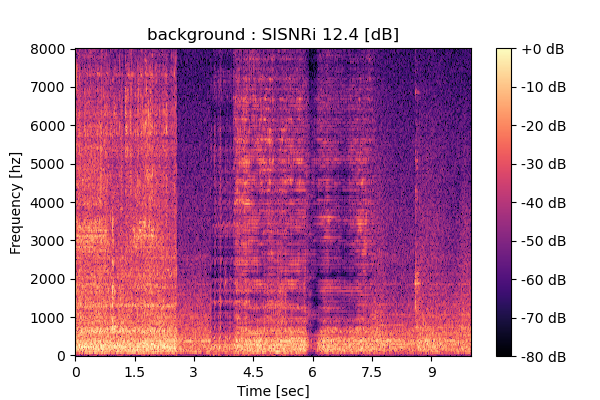
|
Output 2 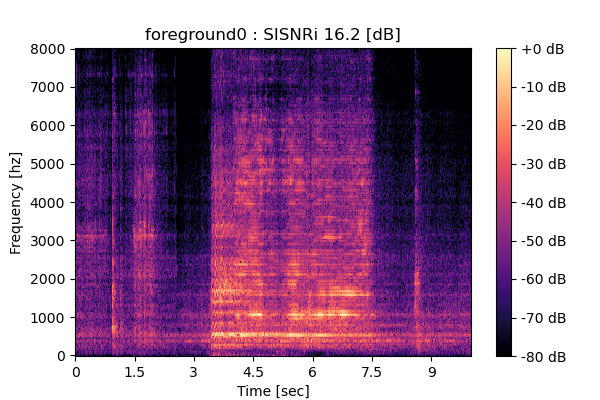
|
Output 3 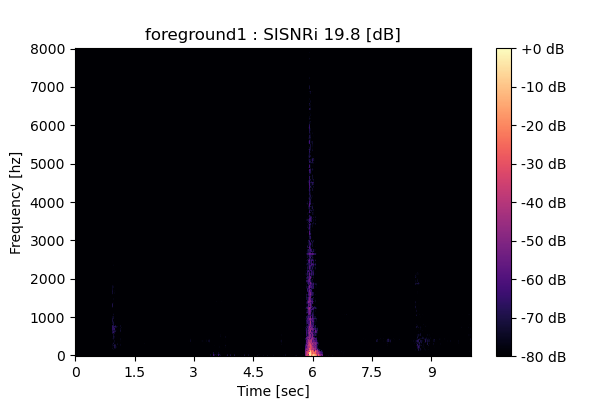
|
Self-Remixing (+ CBS), fine-tuning MixIT pre-trained model
Output 1 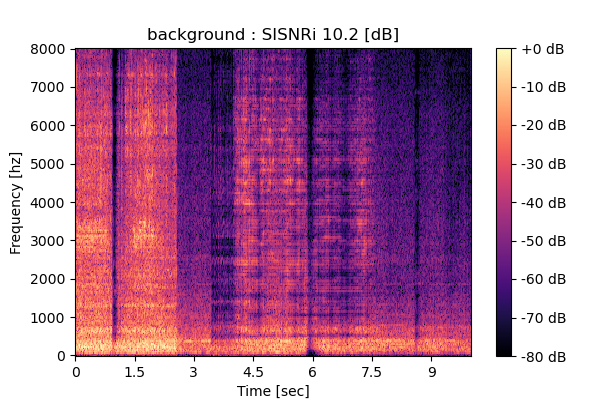
|
Output 2 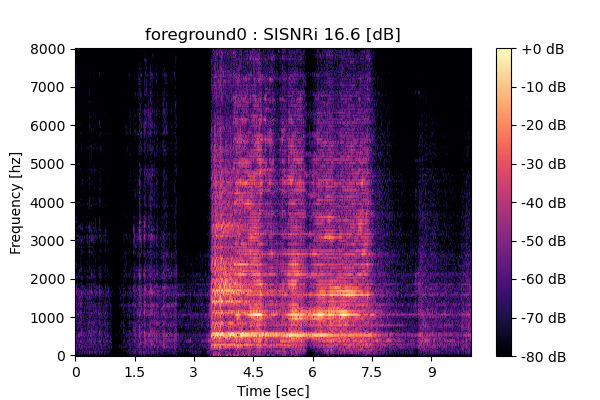
|
Output 3 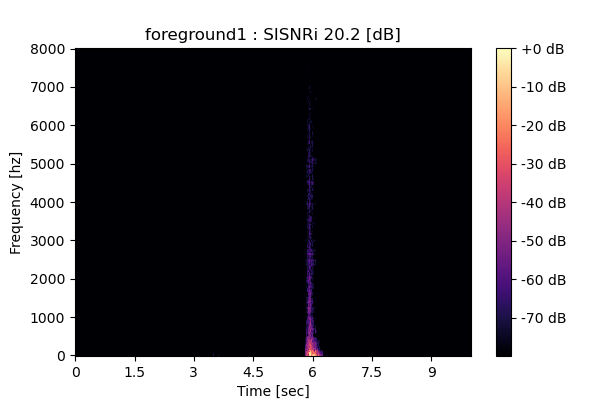
|
4-source mixture
Mixture 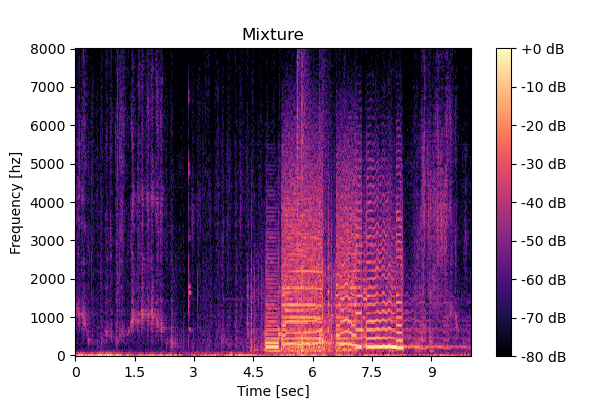 |
Clean source 1 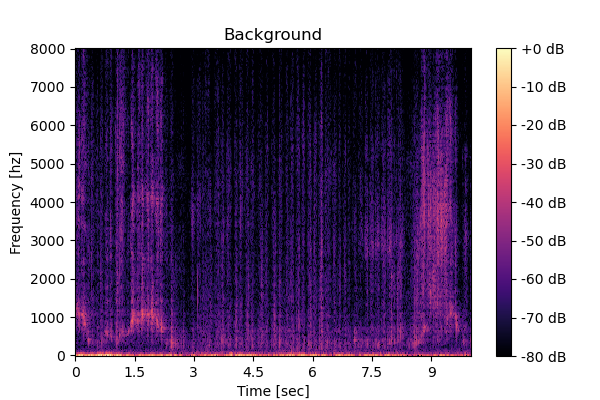
|
Clean source 2 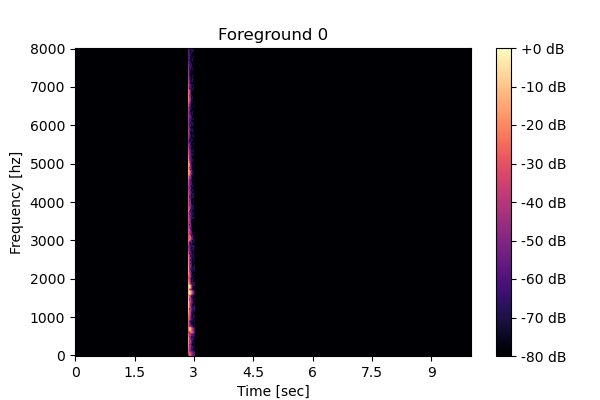
| Clean source 3 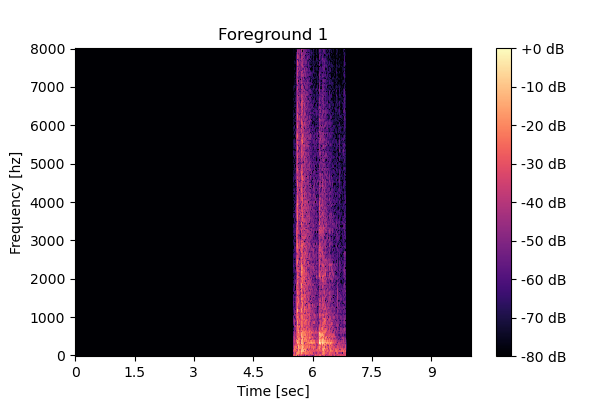
|
Clean source 4 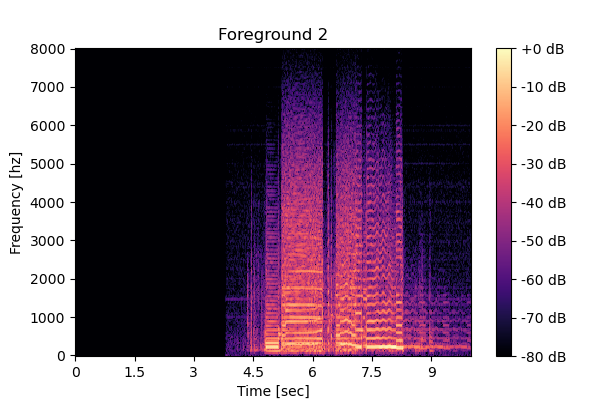
|
MixIT
Output 1 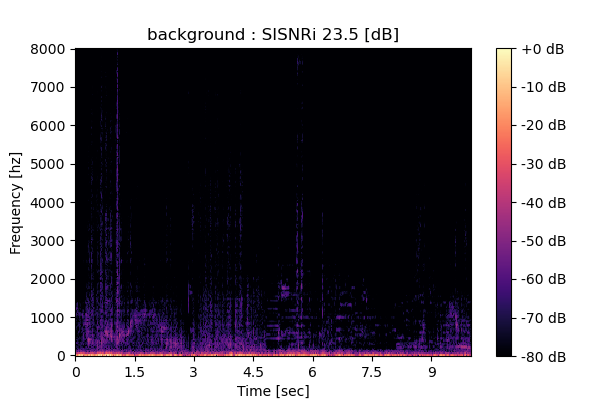
|
Output 2 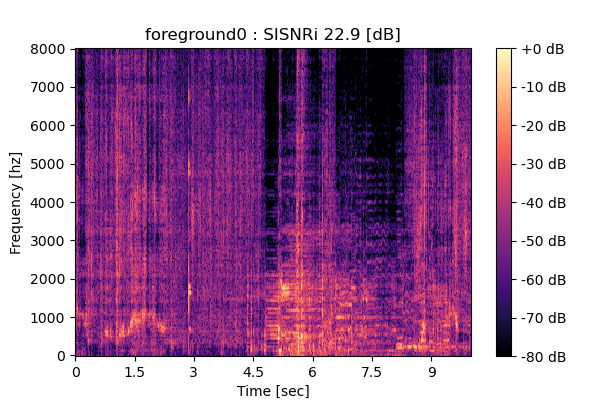
|
Output 3 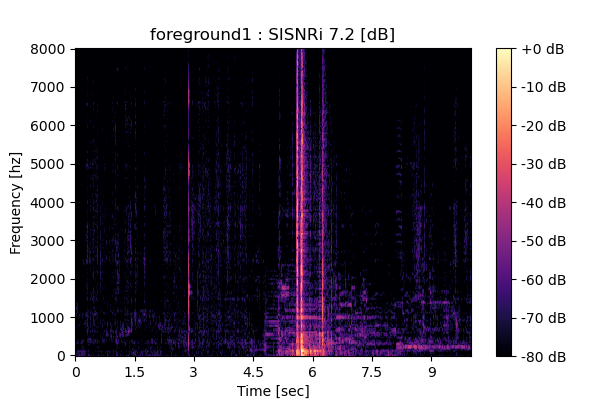
|
Output 3 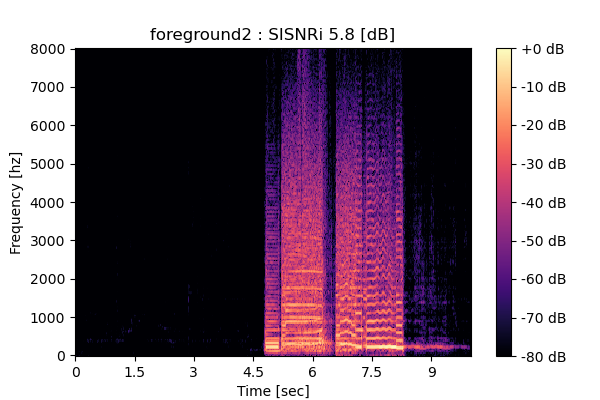
|
MixIT + Sparsity loss
Output 1 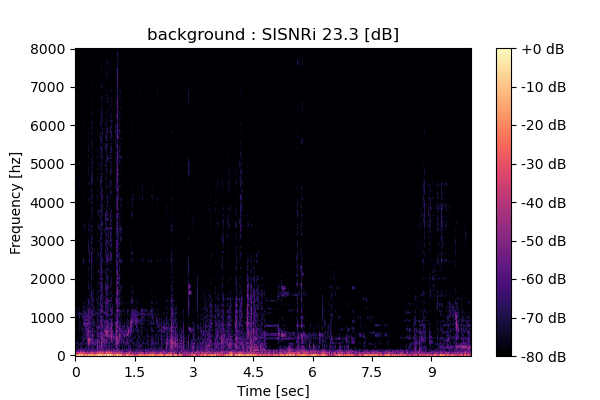
|
Output 2 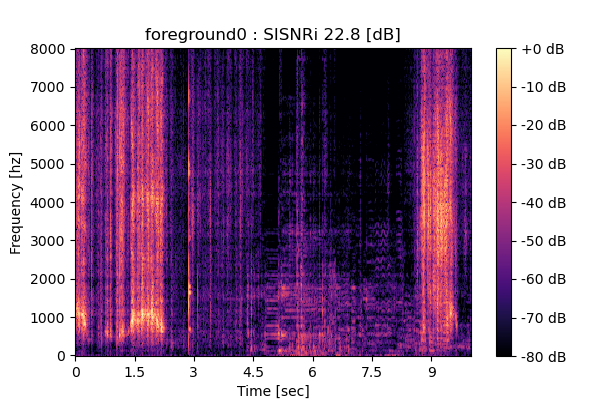
|
Output 3 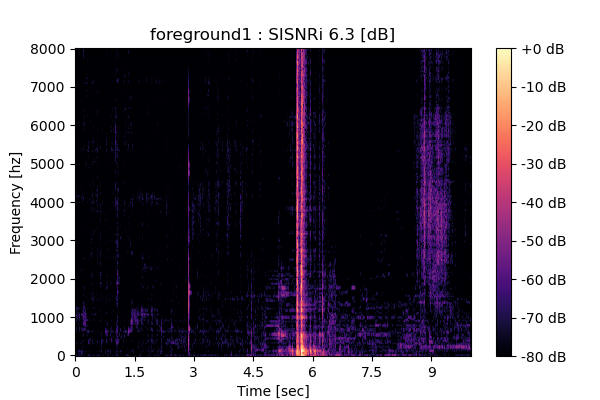
|
Output 4 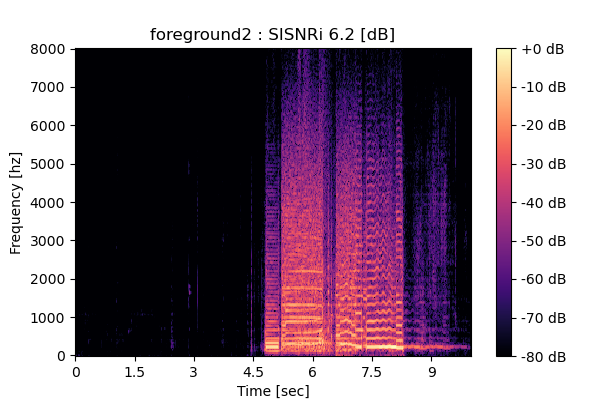
|
Self-Remixing (+ CBS) from scratch
Output 1 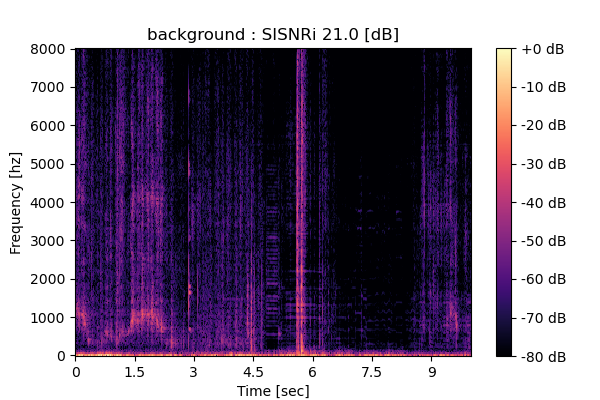
|
Output 2 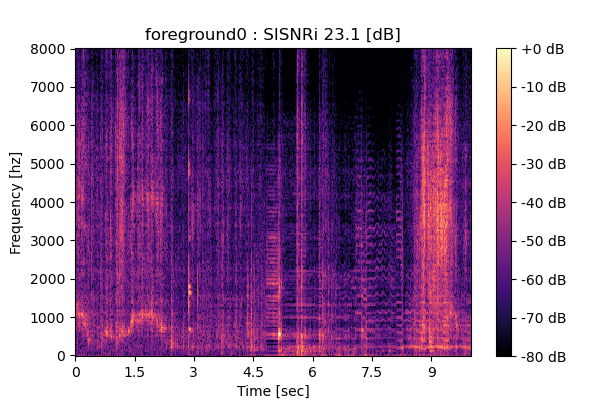
|
Output 3 
|
Output 4 
|
Self-Remixing (+ CBS), fine-tuning MixIT pre-trained model
Output 1 
|
Output 2 
|
Output 3 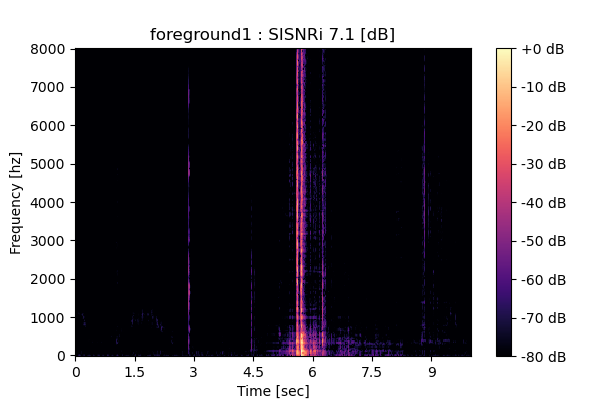
|
Output 4 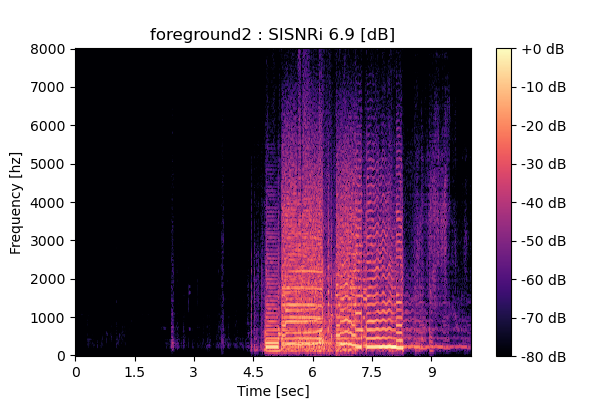
|